Ansigtsgenkendelse - og teknologien bag
Generelle tips til Google Colab
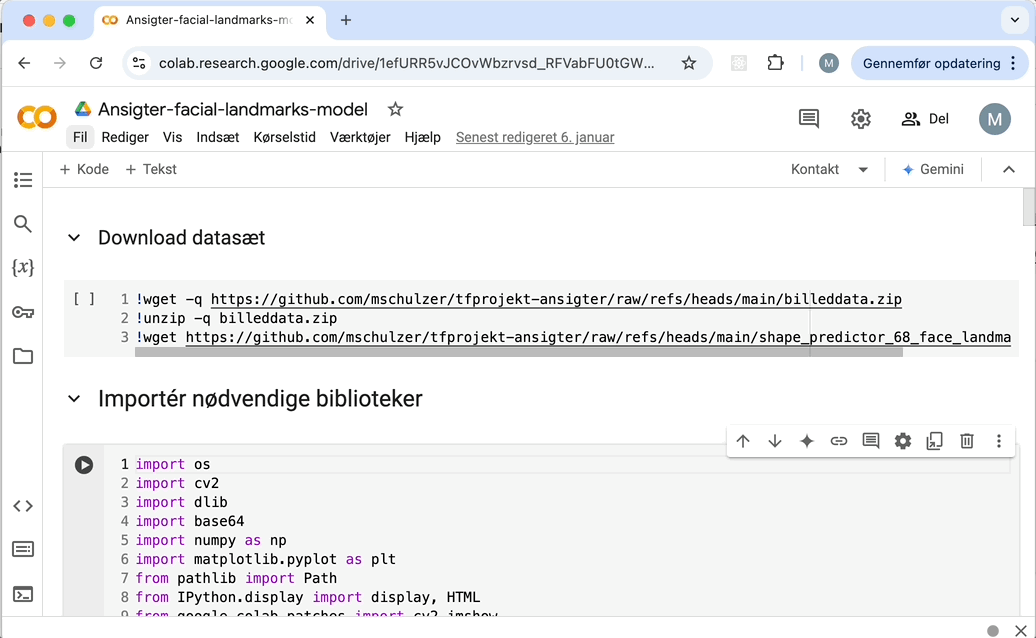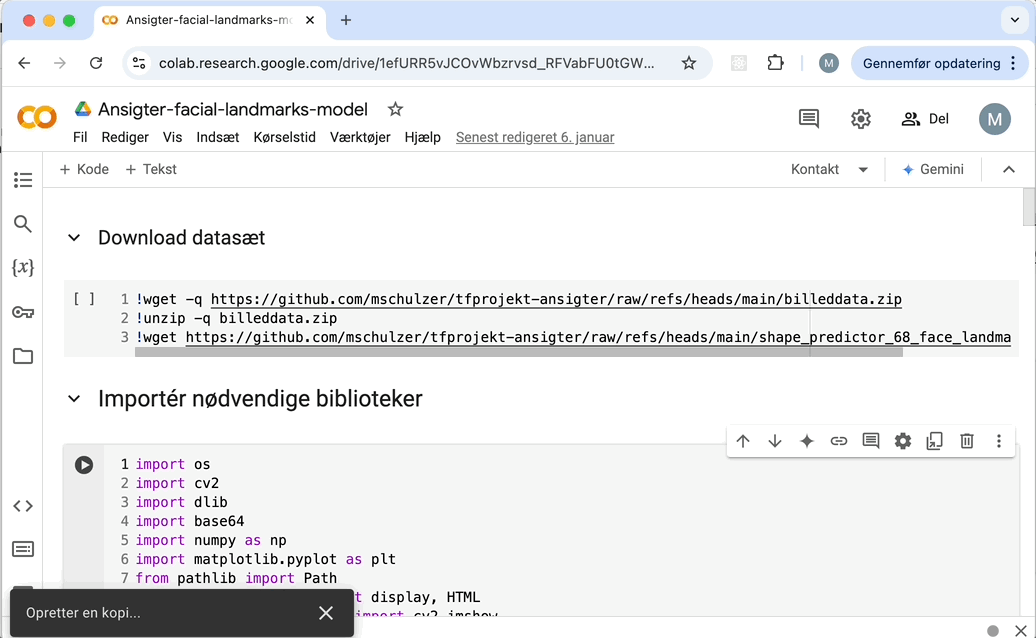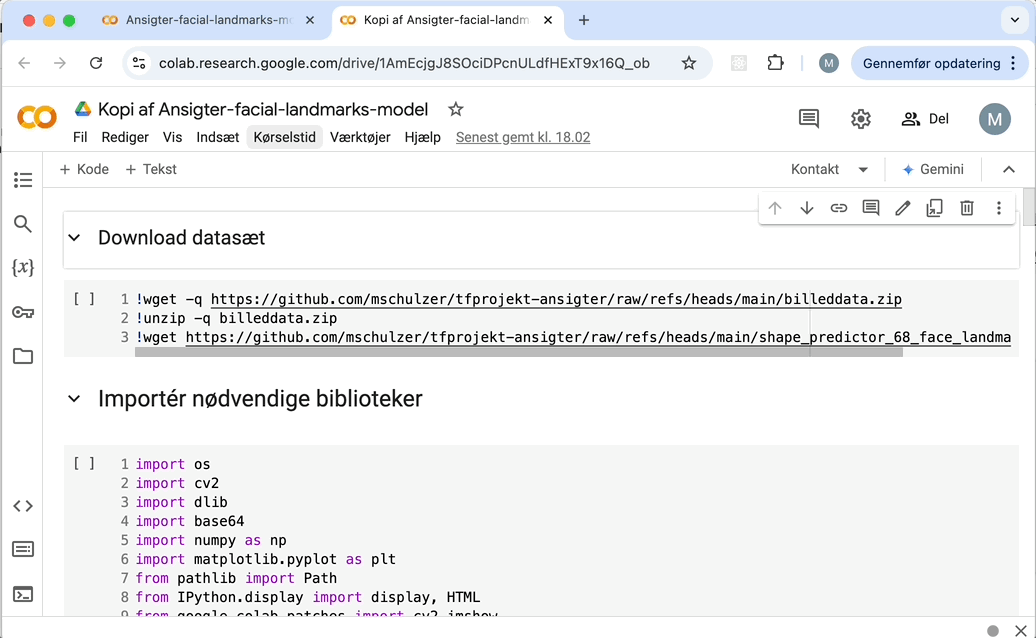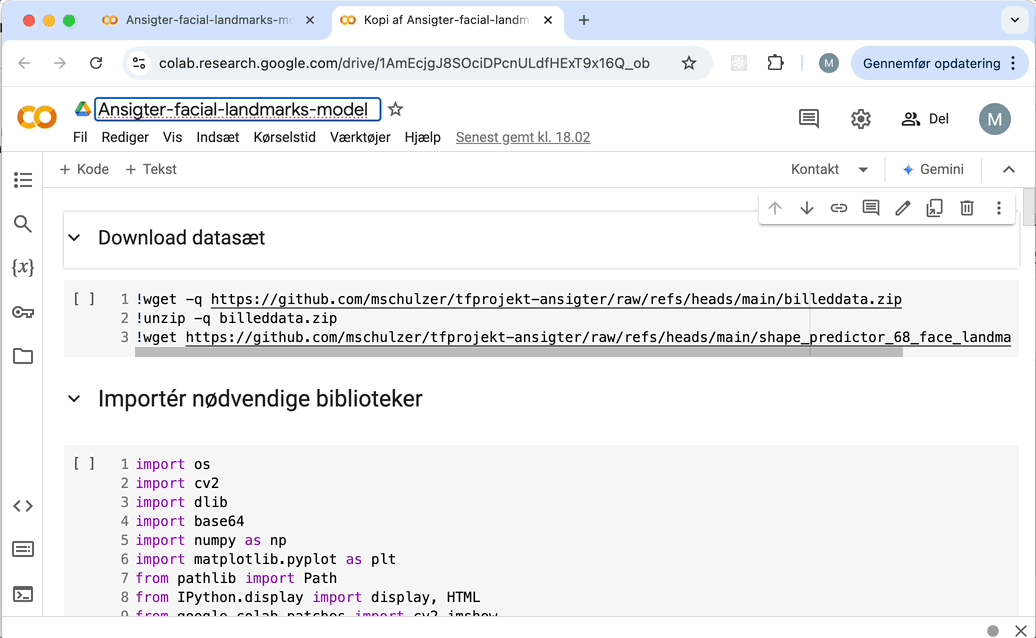
Sådan kopierer du en Notebook:
Sådan uploader du en fil:
Sådan viser du et billede:
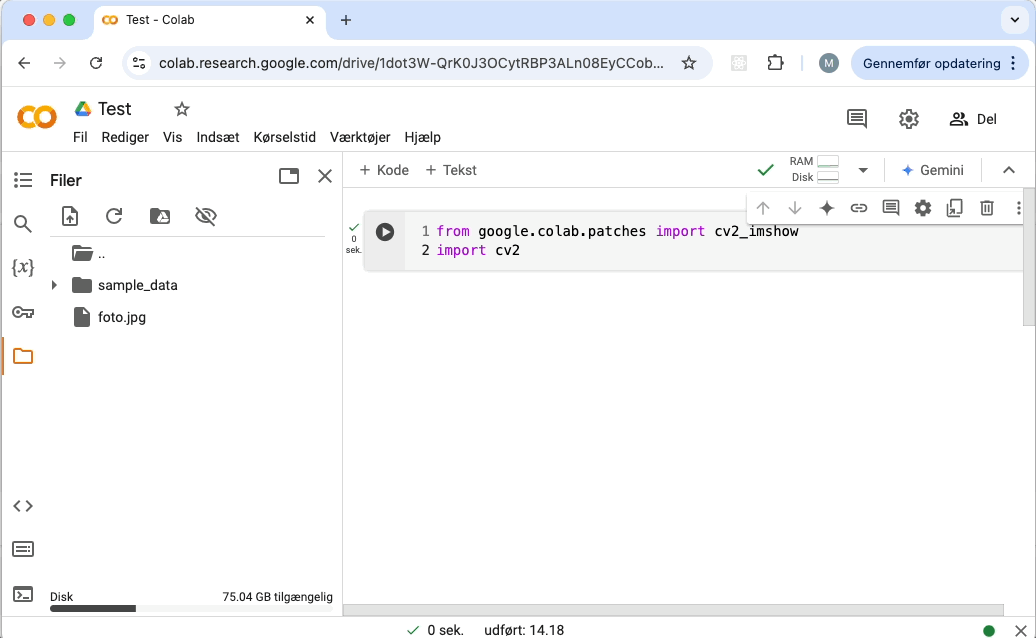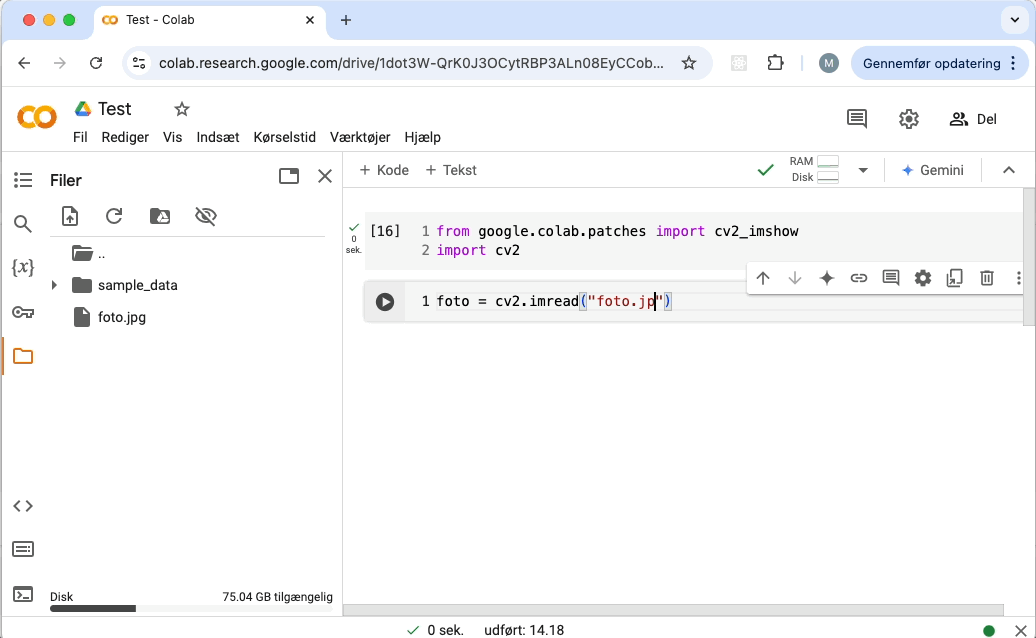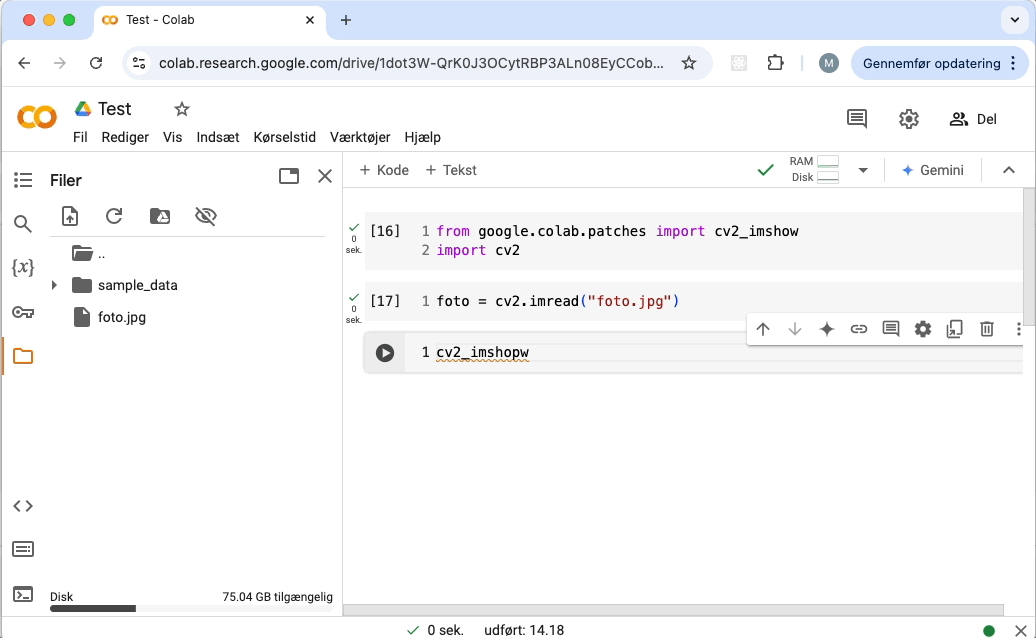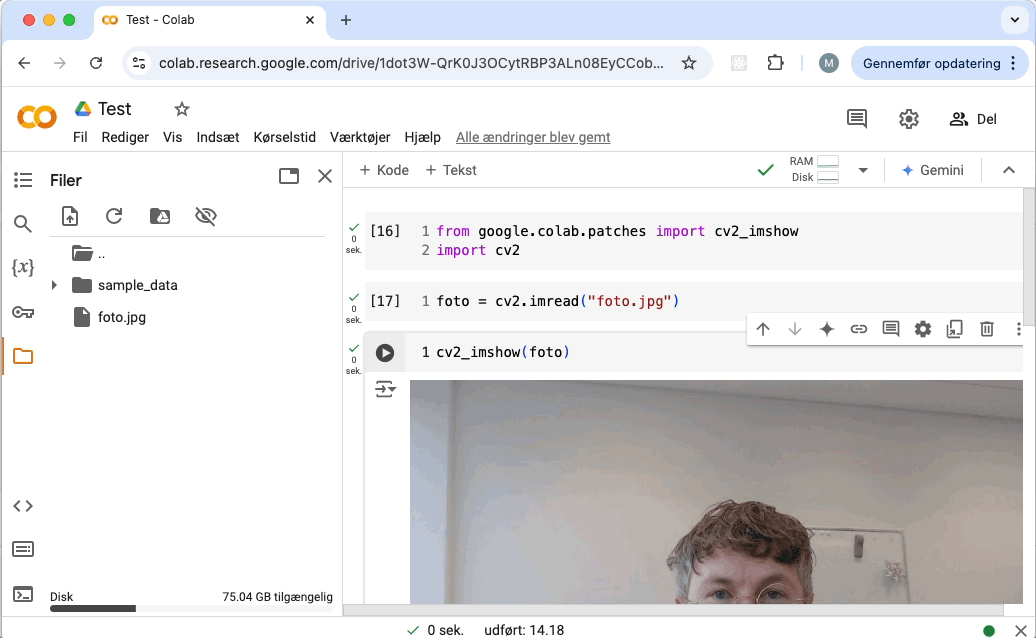
Sådan laver du en mappe:
Modul 3
 Introduktion til modellen: PowerPoint
Introduktion til modellen: PowerPoint
- I får først en helt grundlæggende introduktion til Facial Landmarks.
- Dernæst diskuterer I nedenstående spørgsmål i gruppen.
I kan med fordel kopiere spørgsmålene ind i et Microsoft Word-dokument - eller Google Docs, så I kan vende tilbage til svarene senere.
Forståelsesspørgsmål:
- Hvad forstår man ved "facial landmarks"?
- Hvilke data bygger modellen på?
- Hvilke to grundkomponenter består denne tilgang af?
- Man kunne formulere den sidste grundkomponent i en række trin - hvilke?

I skal arbejde undersøgende ...
I følgende Colab-notebook skal I nu til selv at eksperimentere med teknologien. Overvej først med sidemakkeren, hvorvidt ”ideal-ansigtet” (gengivet til venstre), som Facial Landmarks-modellen arbejder på baggrund af, stemmer overens med jeres intuitioner - og jeres arbejde fra de to foregående moduler?
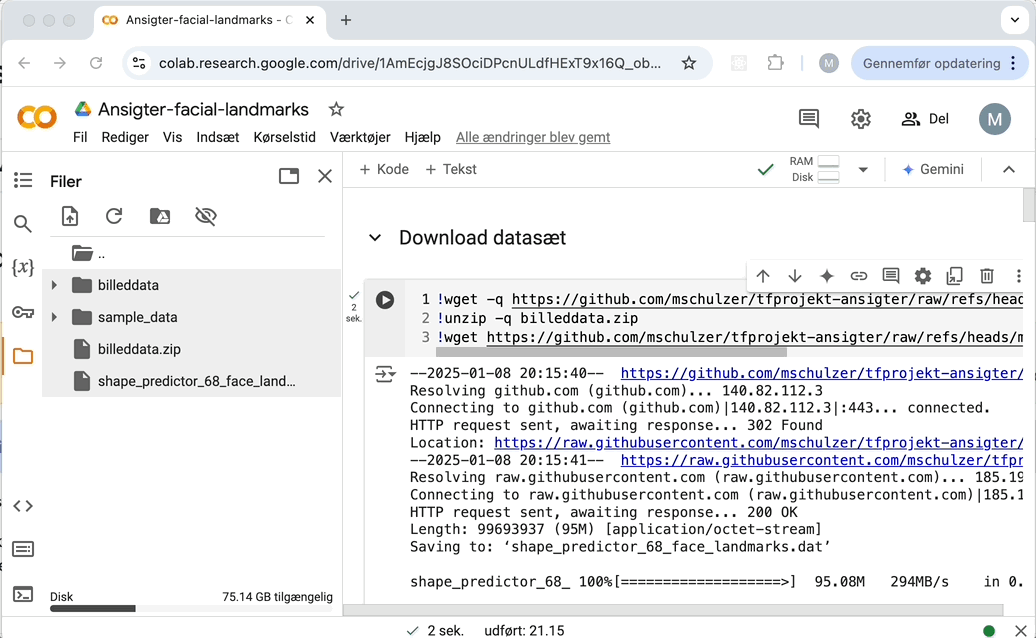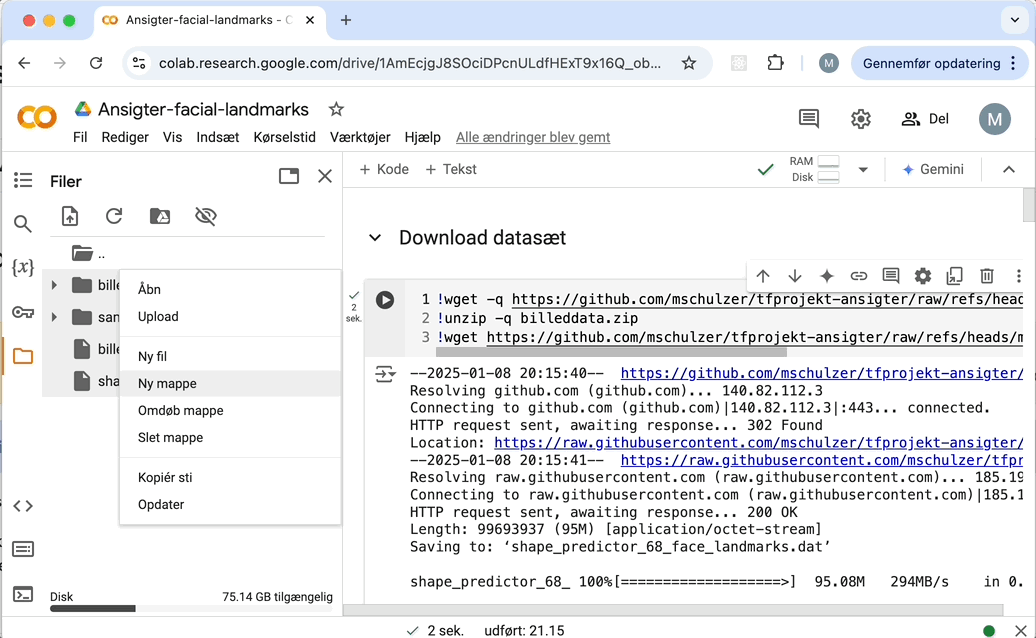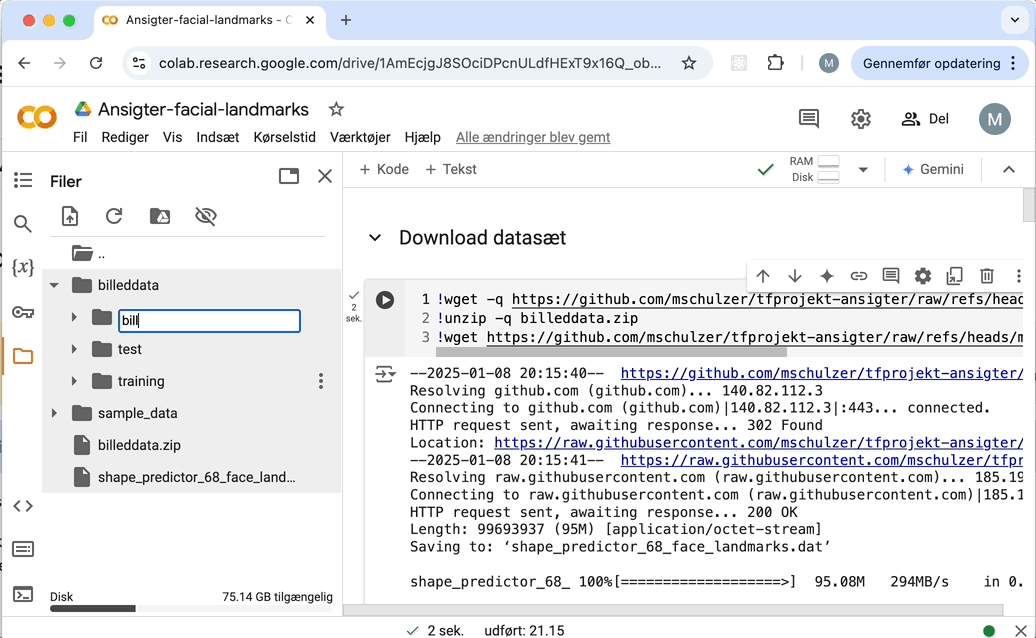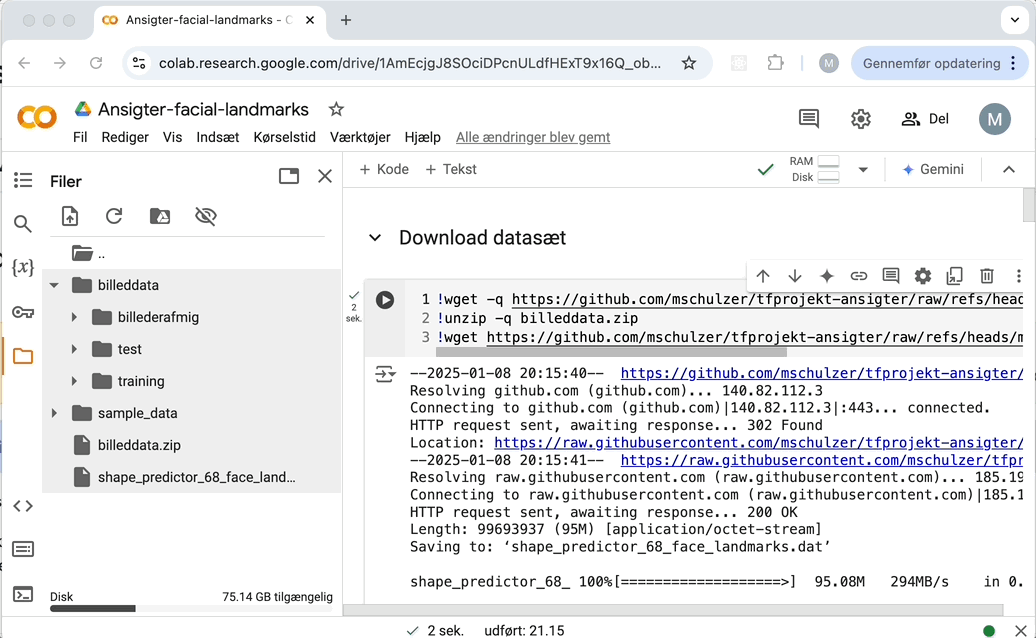
For at komme i gang skal I bruge noget af billedmaterialet fra sidst. Hvis ikke I har disse billeder liggende på computeren, så tag gerne nogle screenshots fra undervisningsmaterialet. Gem disse billeder et sted, hvor I let kan finde dem igen. Følg anvisningerne til at lave mapper og importere filer i Google Colab øverst oppe på denne side (pkt. "Værktøjskasse").
Prøv nu følgende:
- Prøv at ændre i linjerne 22-24 (og tilsvarende for linjerne 31-33) i funktionen
extract_features(). Kan I få modellen til at finde fx afstanden mellem underlæbe og hagespids? Hvor nøjagtig er den? Forsøg jer også med andre afstande. - Upload to billeder af samme person fra gruppen, men hvor vedkommende forsøger at se så forskellig
ud som muligt.
Billederne skal begge ligge i mappen
testunderbilleddata. I skal dernæst indtaste filnavnet på ét af disse billeder mellem parenteserne ireference_image = "..."(søg evt. på reference_image vha. CTRL+F eller COMMAND+F). Kan modellen finde personen? Kan I snyde den? Hvem ligner jer egentlig mindst ud af alle blandt test-billederne - og hvorfor mon? Hvilken matematisk formel bliver i øvrigt brugt til at måle lighed?
Resten af modulet bruger I på at genbesøge nogle af de opgaver, som Modul 2 (Aktivitet 3) sluttede af med. I kan fx forsøge at bruge modellen til at se, om den kan ”spotte” slægtskab. Overvej her i grupper eller med sidemakkeren, hvordan et sådant forsøg skal designes og udføres - og rent praktisk sættes op i Google Colab? Alternativt kan I forsøge jer med jeres foreløbige projektidé.
Modul 4
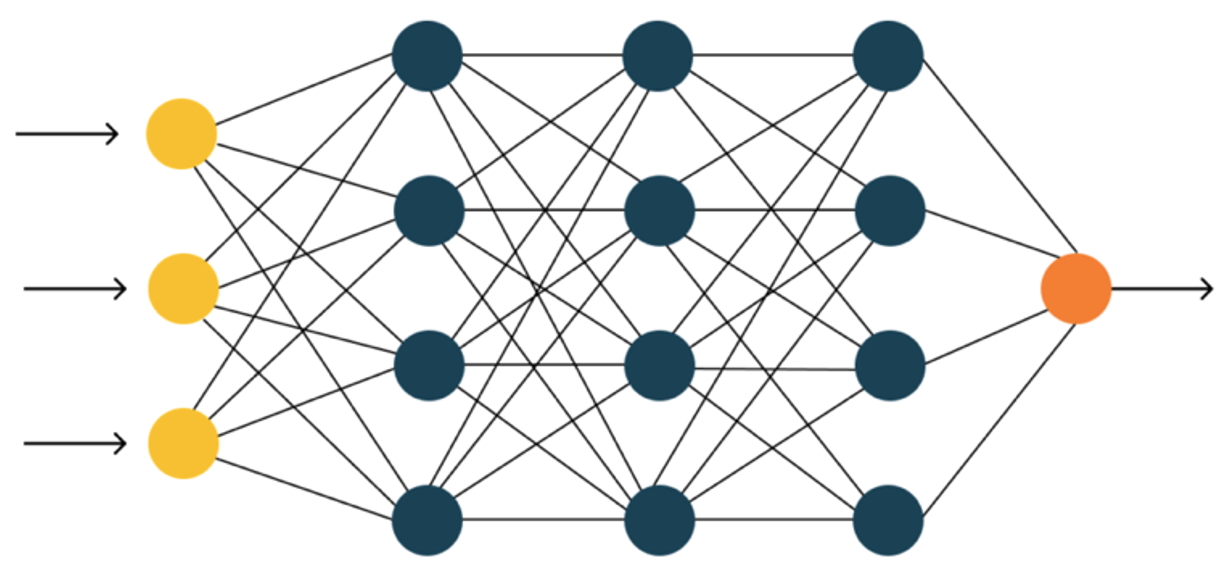
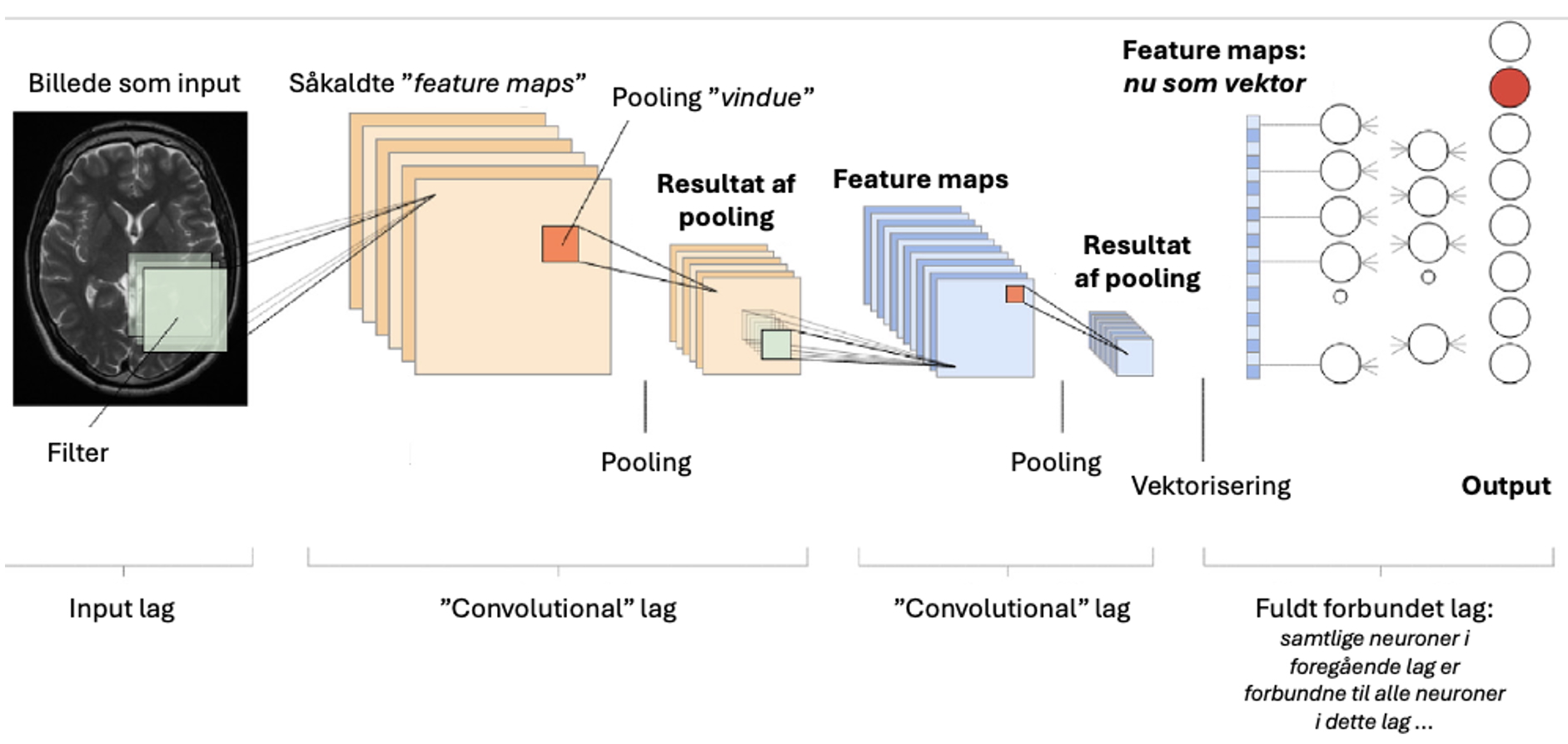
- I får først en helt grundlæggende introduktion til Convolutional Neural Networks.
- Dernæst diskuterer I nedenstående spørgsmål i gruppen.
I kan med fordel kopiere spørgsmålene ind i et Microsoft Word-dokument eller Google Docs, så I kan vende tilbage til svarene senere.
Forståelsesspørgsmål:
- Hvad er et "neuralt netværk"?
- Hvilke data bygger modellen på?
- Hvad forstår man ved foldninger (eng. convolutions)?
I skal igen bruge jeres billedmateriale fra Modul 3 (Aktivitet 2) – og importere dette, ligesom I har gjort tidligere. Kør CNN-modellen på materialet, og overvej undervejs følgende:
- hvor præcis er modellen (... i forhold til sidste gang)?
- hvad ”ser” modellen, hvad er den mao. opmærksom på ved hvert lag?
- er de enkelte filtre (eng. kernels) forståelige - giver de mening?
Hands-on med "pixelering" af billeder i følgende Colab-notebook
Gå ind på følgende Colab-notebook, og følg anvisningerne dér.
Husk at gemme Notebook'en som kopi på dit eget Google Drive. Brug evt. guiden oppe i "Værktøjskassen".
Det er nu tid til at samle op på jeres arbejde med de to modeller. Diskutér nedenstående spørgsmål i gruppen, og sørg for, at I samler jeres overvejelser i et Microsoft Word-dokument eller Google Docs. Arbejdet herfra kan I nemlig bruge i udarbejdelsen af jeres poster.
Diskutér følgende spørgsmål i gruppen:
- Hvilke fordele og ulemper er der ved Facial Landmarks-tilgangen?
- Hvilke fordele og ulemper er der ved CNN’er?
- Hvilke data (og hvor meget) bruger hver model – og hvilke data genererer de?
- Hvilke data tror I umiddelbart gemmes? Og hvor befinder de sig rent fysisk?
- Hvor ”gennemskuelige” er modellerne – helt fra begyndelsen af dette forløb om ansigtsgenkendelse, og dermed også jeres egne, simple modeller, og så til moderne CNN’er?
- Hvilke etiske problemstillinger anser I for mest aktuelle/presserende, nu hvor I har stiftet bekendtskab, teoretisk såvel som praktisk, med forskellige teknologier til ansigtsgenkendelse?
- Er der miljøhensyn forbundet med teknologier som ansigtsgenkendelse – hvilke?
- Er der noget, som I finder væsentlige ift. AI og brugen af ansigtsgenkendelse, som ikke er addresseret i foregående spørgsmål?